
How to Manage Incidents
My 10 Steps Incident Management Process (includes templates)

Incident management is a critical aspect of any organization's workflow, regardless of its size or domain. In today's complex business environment, having a robust incident management system is not only essential for resolving unforeseen problems but also for learning from them and preventing future occurrences.

With over two decades of experience working with both traditional and cloud systems (beginning my career as a system engineer), I have encountered many types of incidents from various perspectives. Depending on your company's size and structure, you may need to handle incidents on your own, lead a dedicated team responsible for incident resolution (typically SRE), or have your team involved in incident resolution as a dependency. In all these cases, it is crucial for an engineering leader or manager to be aware of the incident management process, its various phases, and how to deal with them.
And that is exactly what we will cover today, specifically:
🧠 Understanding Incident Management
🛠️ How to Manage an Incident
🔄 My 10 Steps Incident Management Process
💼 Some Incident Management Tools
Let's get started!
🧠 Understanding Incident Management
To manage incidents effectively, we must first understand what they are, how they can be classified, and the frameworks available to address them.
What is an Incident?
An incident is any unexpected event that disrupts normal operations or threatens the security or integrity of a system. Incidents can manifest in various ways, including:
Technical Outages: unexpected failures in systems or services.
Performance Issues: slow or inefficient operation of software or hardware.
Security Breaches: unauthorized access or exploitation of data, systems, or networks.
Data Loss: unintentional deletion or corruption of data.
Configuration Errors: mistakes in system settings or setup.
User Errors: mistakes made by end-users, such as incorrect data entry.
Software Bugs: flaws or errors in code.
Hardware Failures: physical breakdown or malfunction of hardware components.
Distributed Denial of Service (DDoS) Attacks: deliberate overload of a target's online services.
Phishing and Social Engineering: deceptive tactics to trick individuals into divulging confidential information.
Ransomware Attacks: malicious software that encrypts files and demands payment.
Insider Threats: malicious actions by employees or trusted insiders.
Compliance Violations: failure to adhere to legal, regulatory, or organizational standards.
Environmental Disruptions: natural or man-made events that can damage infrastructure and disrupt operations.
What is Incident Management?
Incident management is a structured approach to addressing and resolving unexpected events, issues, or disruptions in a systematic manner. The primary goal of incident management is to minimize the impact of these incidents on normal operations, services, and customers.
Incident Management Frameworks
Incident management incorporates a systematic process to detect, analyze, and resolve incidents swiftly. There are several notable frameworks for incident management, such as:
A common issue with these frameworks is that they are mostly complex and primarily centered on security. Many are specifically tailored for high-demand contexts such as governments, banks, etc. While the majority of companies may not require these exact frameworks, they can certainly derive inspiration and adapt portions to suit their needs.
Additionally, some well-recognized methodologies can aid in incident management:
These distinct methodologies focus on managing and enhancing IT services and operations. They each possess unique principles, practices, and methods that ensure the efficiency, reliability, and scalability of IT systems. Both ITIL and SRE include a set of best practices specifically designed to manage incidents effectively.
🛠️ Managing Incidents
Despite no specific frameworks or standards for managing generic incidents like outages or performance issues, we can say that every kind of incident handling process should involves a series of well-defined steps aimed at efficiently resolving incidents, minimizing their impact on the organization and learning from mistakes.
These are the main steps that are usually involved in incident management:
Incident identification
Incident categorization
Incident prioritization
Incident response
Incident closure
The above steps provide a comprehensive view of an incident management process, but they may not always be sufficient to properly handle such situations.
♻️ My 10 Steps Incident Management Process
Based on these steps and incorporating best practices from the methodologies I mentioned above, I have developed a step-by-step process to manage incidents. This is the process I've used over the years, but please be aware that incident management depends on many factors and should be adapted according to your team size, product, customers, and so on.
👉 1/10 - Incident Identification
This is where an irregularity in service is first identified. It might come in the form of an automated system alert, a customer complaint, or a report from a staff member.
👉 2/10 - Defining Roles
Before diving into the resolution, it's vital to assign specific roles and responsibilities to the response team. This ensures that everyone knows their part in handling the incident and can work together efficiently. Taking inspiration from Google SRE book, the most important roles are:
🪖 Incident Commander: derived from emergency management practices, the Incident Commander has overall responsibility for managing the incident, making key decisions, coordinating efforts, and overseeing the technical response to minimize confusion and ensure effective communication.
👨💼 Operations Lead: the Operations Lead focuses on the technical aspects of the incident, coordinating efforts to diagnose and resolve the problem, and ensuring that the right technical resources are aligned with the overall incident management strategy.
📢 Communications Lead: responsible for both internal and external communications during an incident, the Communications Lead ensures that all relevant parties are informed and that messaging is clear and consistent.
The process for selecting each of these roles may vary between organizations and situations.
👉 3/10 - Incident Communication
One of the most crucial steps in incident management (often overlooked by tech teams 🤓) is effective communication. You may have the best technicians working to solve an incident, but without proper internal and external communication, success in handling the incident is unlikely.
Therefore, as soon as a Communication Lead is assigned, their responsibility is to promptly initiate incident status communication. Although there might not be many details initially, it is vital to establish communication channels with the Customer Support team, stakeholders, and customers as soon as possible and maintain continuous updates until the incident is fully resolved.
👉 4/10 - Logging
Recording the incident with all relevant details is essential. As soon as roles are defined, IC (Incident Commander) should create a document to start logging all the activities. This document should be regularly updated during the incident and will serve at the end of the process to create an extensive report of what happened and how the incident was handled.
👉 5/10 - Define Incident Severity
Not all incidents are of equal importance, so they must be ranked according to their urgency and impact on the business. This is often referred to as "Severity," which is calculated using a matrix that puts in relation Impact and Urgency.

Impact: is typically assessed by considering the number of users affected by the service disruption.
Urgency: typically assesses how pressing it is to address the incident promptly. It represents the time-critical nature of an incident or issue and the need for immediate attention and resolution.
Having a clear idea of Severity levels around the team and the company, is crucial. It ensures that critical incidents are handled first, enabling efficient allocation of resources and alignment with business needs.
👉 6/10 - Initial Diagnosis
The first responders conduct a preliminary analysis to understand the incident's nature. Typically led by the Operations Lead, this stage involves basic troubleshooting, log review, and consultation of documentation to gain initial insights into the problem. In well-structured organizations, a dedicated SRE Team often handles this responsibility. This phase plays a critical role in determining whether the incident can be swiftly resolved or requires further investigation.
👉 7/10 - Escalation
If the incident cannot be resolved by the initial responders or SRE team, it may be escalated to specialists with more expertise or even higher-level management. Escalation ensures that the incident is addressed by those best equipped to handle it, whether due to its complexity, sensitivity, or other factors.
👉 8/10 - Investigation and Diagnosis
A more detailed examination of the incident is carried out to uncover the root cause. This investigation may require deep analysis, consultation with subject matter experts, or the use of specialized diagnostic tools. Identifying the underlying cause is key to finding the right solution.
👉 9/10 - Resolution and Recovery
Once the root cause is known, a fix can be implemented, and normal service restored. This might involve applying a software patch, changing configurations, restarting services, or other remedial actions. The focus here is on resolving the issue as quickly and effectively as possible, minimizing disruption.
👉 10/10 - Post Mortem
The incident is formally closed in this final step. This includes a comprehensive documentation of the incident, including the resolution, the time taken to resolve it, lessons learned, and confirmation that all related tasks are complete. Closure ensures a complete record for future reference and signifies the end of the incident management process.
The outcome of this last step of the process is usually recorded in a document called "No-Blame Post Mortem".
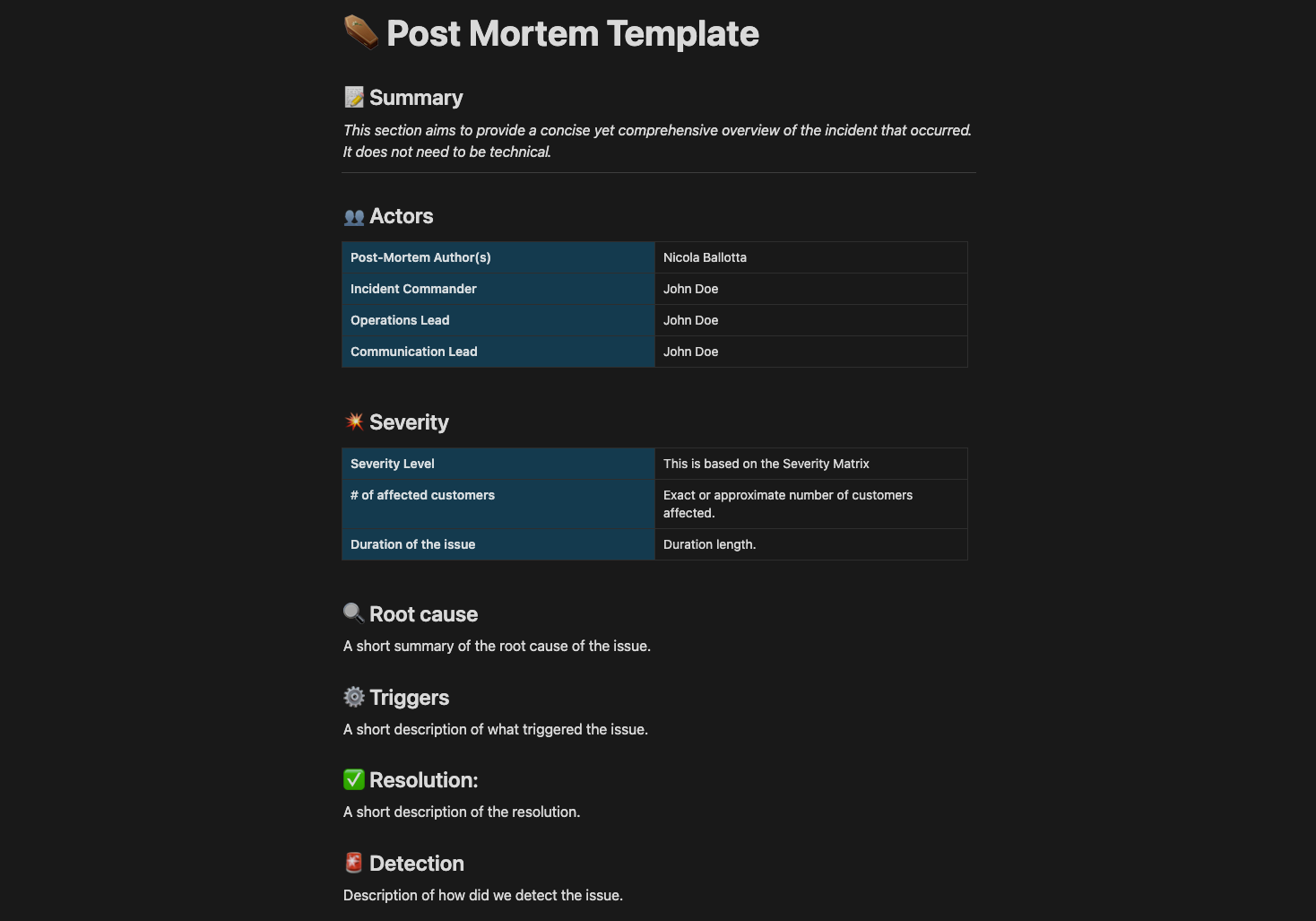
A "no-blame postmortem" refers to a review process after an incident where the focus is on understanding what happened and why, rather than assigning blame or fault to individuals. This approach promotes a culture of learning and continuous improvement.